Welcome to the SeaweedFS wiki!
SeaweedFS is a versatile and efficient storage system designed to meet the needs of modern sysadmins managing a mix of blob, object, file, and data warehouse storage requirements. Its architecture guarantees fast access times, with constant-time (O(1)) disk seeks, regardless of the size of the dataset. This makes it an excellent choice for environments where speed and efficiency are critical.
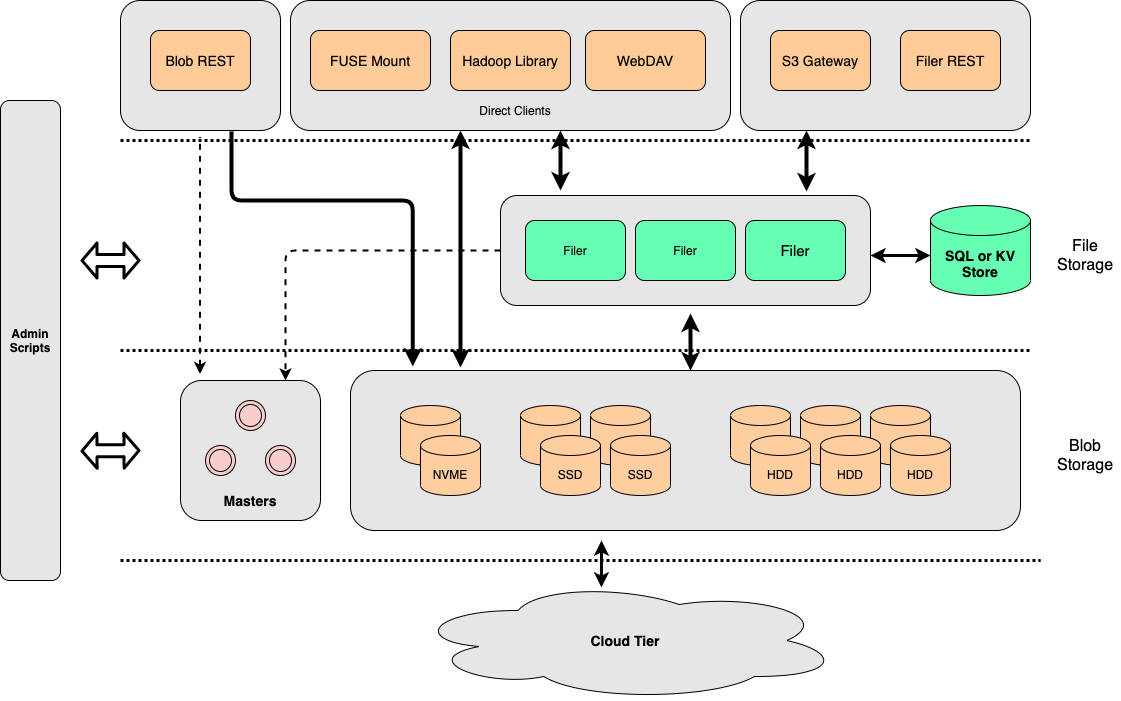
SeaweedFS is organized into several layers, each serving a different storage need:
- Blob Storage is the foundation, comprising master servers, volume servers, and a cloud tier for infinite scalability.
- File Storage builds on Blob Storage by adding filer servers for managing filesystem-like operations.
- Object Storage extends File Storage with S3-compatible servers, making it a breeze to integrate with existing S3 workflows.
- Data Warehouse capabilities are integrated into File Storage, offering compatibility with big data frameworks like Hadoop, Spark, and Flink, through Hadoop-compatible libraries.
- FUSE Mount allows File Storage to be directly mounted in user space on clients, supporting common use cases like FUSE mounts and Kubernetes persistent volumes.
SeaweedFS stands out for its high performance, scalability, and flexibility. It features:
- Fast key-to-file mapping with minimal disk seek time.
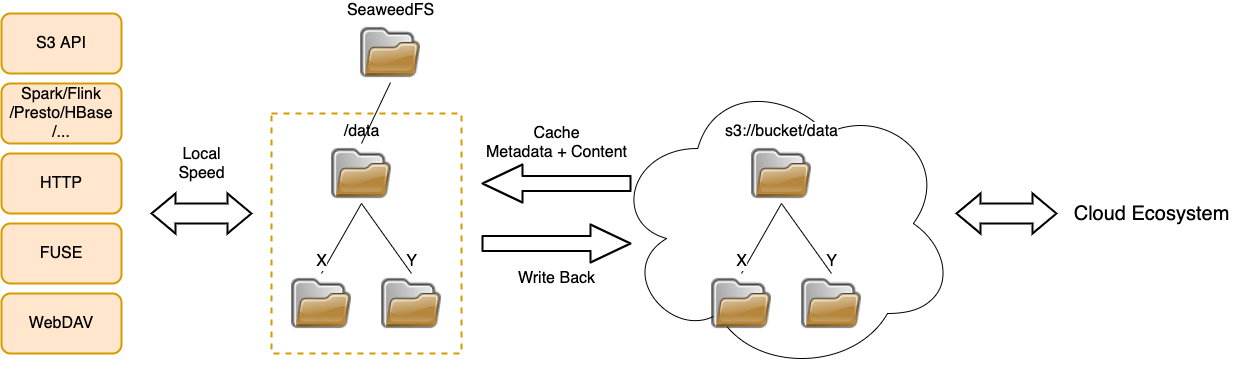
- Customizable tiered storage that intelligently places data based on activity, moving less active data to cheaper cloud storage.
- Elastic scalability, easily expanding capacity by adding volume servers.
- A robust, high-performance, S3-compatible object store that can serve as an in-house alternative to HDFS.
The system is designed for high availability and durability, with features like:
- No single point of failure (SPOF), supporting active-active asynchronous replication and erasure coding for data protection.
- Support for file checksums to ensure data integrity.
- Rack and data center aware replication to enhance reliability.
- Flexible metadata management, compatible with a variety of popular databases and storage systems.
For sysadmins, SeaweedFS simplifies operations significantly. Adding capacity is as straightforward as integrating more volume servers. The system's architecture allows for easy data migration and backup, supporting a wide array of backend stores for metadata. This makes SeaweedFS an adaptable and reliable choice for managing diverse and demanding storage environments.
Here is the white paper for SeaweedFS Architecture.pdf
Roadmap
- Getting Started: If you are a user wanting to try out SeaweedFS.
- Production Setup: this lays out a more serious configuration designed for large volumes of traffic and high relability.
- Components: How the services fit together.
- Benchmarks: the measured performance of SeaweedFS.
- FAQ: things we should work to include in the main documentation.
- Applications, Use-Cases and Actual-Users: inspiration and ideas for how you might use SeaweedFS.