Native ONNX to Inference Engine backend #21066Resolves#21052
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or other license that is incompatible with OpenCV
- [x] The PR is proposed to proper branch
- [x] There is reference to original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
- [ ] The feature is well documented and sample code can be built with the project CMake
Supporting protobuf v22 and later(with abseil-cpp/C++17) #24372
fix https://github.com/opencv/opencv/issues/24369
related https://github.com/opencv/opencv/issues/23791
1. This patch supports external protobuf v22 and later, it required abseil-cpp and c++17.
Even if the built-in protobuf is upgraded to v22 or later,
the dependency on abseil-cpp and the requirement for C++17 will continue.
2. Some test for caffe required patched protobuf, so this patch disable them.
This patch is tested by following libraries.
- Protobuf: /usr/local/lib/libprotobuf.so (4.24.4)
- abseil-cpp: YES (20230125)
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
GSoC Add ONNX Support for GatherElements #24092
Merge with: https://github.com/opencv/opencv_extra/pull/1082
Adds support to the ONNX operator GatherElements [operator docs](https://github.com/onnx/onnx/blob/main/docs/Operators.md#GatherElements)
Added tests to opencv_extra at pull request https://github.com/opencv/opencv_extra/pull/1082
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Fixed CumSum layer inplace flag #24367
When exclusive is false:
dst[i] = dst[i-1] + src[i]
When exclusive is true:
dst[i] = dst[i-1] + src[i-1]
So CumSum layer can be inplace only when exclusive flag is false.
* remove Conformance from test names
* integrate neon optimization into default
* quick fix: define CV_NEON_AARCH64 0 for non NEON platforms
* remove var batch that leads to memory leak
* put neon code back to fast_gemm_kernels.simd
* reorganize code to reduce duplicate code
Rewrite Universal Intrinsic code: float related part #24325
The goal of this series of PRs is to modify the SIMD code blocks guarded by CV_SIMD macro: rewrite them by using the new Universal Intrinsic API.
The series of PRs is listed below:
#23885 First patch, an example
#23980 Core module
#24058 ImgProc module, part 1
#24132 ImgProc module, part 2
#24166 ImgProc module, part 3
#24301 Features2d and calib3d module
#24324 Gapi module
This patch (hopefully) is the last one in the series.
This patch mainly involves 3 parts
1. Add some modifications related to float (CV_SIMD_64F)
2. Use `#if (CV_SIMD || CV_SIMD_SCALABLE)` instead of `#if CV_SIMD || CV_SIMD_SCALABLE`,
then we can get the `CV_SIMD` module that is not enabled for `CV_SIMD_SCALABLE` by looking for `if CV_SIMD`
3. Summary of `CV_SIMD` blocks that remains unmodified: Updated comments
- Some blocks will cause test fail when enable for RVV, marked as `TODO: enable for CV_SIMD_SCALABLE, ....`
- Some blocks can not be rewrited directly. (Not commented in the source code, just listed here)
- ./modules/core/src/mathfuncs_core.simd.hpp (Vector type wrapped in class/struct)
- ./modules/imgproc/src/color_lab.cpp (Array of vector type)
- ./modules/imgproc/src/color_rgb.simd.hpp (Array of vector type)
- ./modules/imgproc/src/sumpixels.simd.hpp (fixed length algorithm, strongly ralated with `CV_SIMD_WIDTH`)
These algorithms will need to be redesigned to accommodate scalable backends.
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [ ] I agree to contribute to the project under Apache 2 License.
- [ ] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [ ] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [ ] The feature is well documented and sample code can be built with the project CMake
Fixed CumSum dnn layer #24353Fixes#20110
The algorithm had several errors, so I rewrote it.
Also the layer didn't work with non constant axis tensor. Fixed it.
Enabled CumSum layer tests from ONNX conformance.
OpenVINO backend for INT8 models #23987
### Pull Request Readiness Checklist
TODO:
- [x] DetectionOutput layer (https://github.com/opencv/opencv/pull/24069)
- [x] Less FP32 fallbacks (i.e. Sigmoid, eltwise sum)
- [x] Accuracy, performance tests (https://github.com/opencv/opencv/pull/24039)
- [x] Single layer tests (convolution)
- [x] ~~Fixes for OpenVINO 2022.1 (https://pullrequest.opencv.org/buildbot/builders/precommit_custom_linux/builds/100334)~~
Performace results for object detection model `coco_efficientdet_lite0_v1_1.0_quant_2021_09_06.tflite`:
| backend | performance (median time) |
|---|---|
| OpenCV | 77.42ms |
| OpenVINO 2023.0 | 10.90ms |
CPU: `11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz`
Serialized model per-layer stats (note that Convolution should use `*_I8` primitives if they are quantized correctly): https://gist.github.com/dkurt/7772bbf1907035441bb5454f19f0feef
---
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
dnn: merge tests from test_halide_layers to test_backends #24283
Context: https://github.com/opencv/opencv/pull/24231#pullrequestreview-1628649980
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Add Support for Einsum Layer #24037
### This PR adding support for [Einsum Layer](https://pytorch.org/docs/stable/generated/torch.einsum.html) (in progress).
This PR is currently not to be merged but only reviewed. Test cases are located in [#1090](https://github.com/opencv/opencv_extra/pull/1090)RP in OpenCV extra
**DONE**:
- [x] 2-5D GMM support added
- [x] Matrix transpose support added
- [x] Reduction type comupte 'ij->j'
- [x] 2nd shape computation - during forward
**Next PRs**:
- [ ] Broadcasting reduction "...ii ->...i"
- [ ] Add lazy shape deduction. "...ij, ...jk->...ik"
- [ ] Add implicit output computation support. "bij,bjk ->" (output subscripts should be "bik")
- [ ] Add support for CUDA backend
- [ ] BatchWiseMultiply optimize
**Later in 5.x version (requires support for 1D matrices)**:
- [ ] Add 1D vector multiplication support
- [ ] Inter product "i, i" (problems with 1D shapes)
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
* first commit
* turned C from input to constant; force C constant in impl; better handling 0d/1d cases
* integrate with gemm from ficus nn
* fix const inputs
* adjust threshold for int8 tryQuantize
* adjust threshold for int8 quantized 2
* support batched gemm and matmul; tune threshold for rcnn_ilsvrc13; update googlenet
* add gemm perf against innerproduct
* add perf tests for innerproduct with bias
* fix perf
* add memset
* renamings for next step
* add dedicated perf gemm
* add innerproduct in perf_gemm
* remove gemm and innerproduct perf tests from perf_layer
* add perf cases for vit sizes; prepack constants
* remove batched gemm; fix wrong trans; optimize KC
* remove prepacking for const A; several fixes for const B prepacking
* add todos and gemm expression
* add optimized branch for avx/avx2
* trigger build
* update macros and signature
* update signature
* fix macro
* fix bugs for neon aarch64 & x64
* add backends: cuda, cann, inf_ngraph and vkcom
* fix cuda backend
* test commit for cuda
* test cuda backend
* remove debug message from cuda backend
* use cpu dispatcher
* fix neon macro undef in dispatcher
* fix dispatcher
* fix inner kernel for neon aarch64
* fix compiling issue on armv7; try fixing accuracy issue on other platforms
* broadcast C with beta multiplied; improve func namings
* fix bug for avx and avx2
* put all platform-specific kernels in dispatcher
* fix typos
* attempt to fix compile issues on x64
* run old gemm when neon, avx, avx2 are all not available; add kernel for armv7 neon
* fix typo
* quick fix: add macros for pack4
* quick fix: use vmlaq_f32 for armv7
* quick fix for missing macro of fast gemm pack f32 4
* disable conformance tests when optimized branches are not supported
* disable perf tests when optimized branches are not supported
* decouple cv_try_neon and cv_neon_aarch64
* drop googlenet_2023; add fastGemmBatched
* fix step in fastGemmBatched
* cpu: fix initialization ofb; gpu: support batch
* quick followup fix for cuda
* add default kernels
* quick followup fix to avoid macro redef
* optmized kernels for lasx
* resolve mis-alignment; remove comments
* tune performance for x64 platform
* tune performance for neon aarch64
* tune for armv7
* comment time consuming tests
* quick follow-up fix
In the previous code, there was a memory leak issue where the
previously allocated memory was not freed upon a failed realloc
operation. This commit addresses the problem by releasing the old
memory before setting the pointer to NULL in case of a realloc failure.
This ensures that memory is properly managed and avoids potential
memory leaks.
Added default dimension value to tensorflow ArgMax and ArgMin layers #24266
Added default dimension value to tensorflow ArgMax and ArgMin layers.
Added exception when accessing layer's input with out of range index.
Fixes https://bugs.chromium.org/p/oss-fuzz/issues/detail?id=48452
Use ngraph::Output in OpenVINO backend wrapper #24196
### Pull Request Readiness Checklist
resolves https://github.com/opencv/opencv/issues/24102
* Use `ngraph::Output<ngraph::Node>>` insead of `std::shared_ptr<ngraph::Node>` as a backend wrapper. It lets access to multi-output nodes: 588ddf1b18/modules/dnn/src/net_openvino.cpp (L501-L504)
* All layers can be customizable with OpenVINO >= 2022.1. nGraph reference code used for default layer implementation does not required CPU plugin also (might be tested by commenting CPU plugin at `/opt/intel/openvino/runtime/lib/intel64/plugins.xml`).
* Correct inference if only intermediate blobs requested.
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
If building with -mcpu=native or any other setting which implies the current
CPU has FP16 but with intrinsics disabled, we mistakenly try to use it even
though convolution.hpp conditionally defines it correctly based on whether
we should *use it*. convolution.cpp on the other hand was mismatched and
trying to use it if the CPU supported it, even if not enabled in the build
system.
Make the guards match.
Bug: https://bugs.gentoo.org/913031
Signed-off-by: Sam James <sam@gentoo.org>
OCL_FP16 MatMul with large batch
* Workaround FP16 MatMul with large batch
* Fix OCL reinitialization
* Higher thresholds for INT8 quantization
* Try fix gemm_buffer_NT for half (columns)
* Fix GEMM by rows
* Add batch dimension to InnerProduct layer test
* Fix Test_ONNX_conformance.Layer_Test/test_basic_conv_with_padding
* Batch 16
* Replace all vload4
* Version suffix for MobileNetSSD_deploy Caffe model
dnn: cleanup of tengine backend #24122🚀 Cleanup for OpenCV 5.0. Tengine backend is added for convolution layer speedup on ARM CPUs, but it is not maintained and the convolution layer on our default backend has reached similar performance to that of Tengine.
Tengine backend related PRs:
- https://github.com/opencv/opencv/pull/16724
- https://github.com/opencv/opencv/pull/18323
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Invalid memory access fix for ONNX split layer parser #24076#24101
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work https://github.com/opencv/opencv/issues/24076
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
TFLite models on different backends (tests and improvements) #24039
### Pull Request Readiness Checklist
* MaxUnpooling with OpenVINO
* Fully connected with transposed inputs/weights with OpenVINO
* Enable backends tests for TFLite (related to https://github.com/opencv/opencv/issues/23992#issuecomment-1640691722)
* Increase existing tests thresholds
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Resolve uncovered CUDA dnn layer #24080
### Pull Request Readiness Checklist
* Gelu activation layer on CUDA
* Try to relax GEMM from ONNX
resolves https://github.com/opencv/opencv/issues/24064
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Remove legacy nGraph logic #24072
### Pull Request Readiness Checklist
TODO:
- [x] Test with OpenVINO 2021.4 (tested locally)
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
DetectionOutput layer on OpenVINO without limitations #24069
### Pull Request Readiness Checklist
required for https://github.com/opencv/opencv/pull/23987
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
PReLU with element-wise scales #24056
### Pull Request Readiness Checklist
resolves https://github.com/opencv/opencv/issues/24051
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Update opencv dnn to support cann version >=6.3 #23936
1.modify the search path of "libopsproto.so" in OpenCVFindCANN.cmake
2.add the search path of "libgraph_base.so" in OpenCVFindCANN.cmake
3.automatic check Ascend socVersion,and test on Ascend310/Ascend310B/Ascend910B well
[TFLite] Pack layer and other fixes for SSD from Keras #24004
### Pull Request Readiness Checklist
resolves https://github.com/opencv/opencv/issues/23992
**Merge with extra**: https://github.com/opencv/opencv_extra/pull/1076
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
DNN: optimize the speed of general Depth-wise #23952
Try to solve the issue: https://github.com/opencv/opencv/issues/23941
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [ ] The feature is well documented and sample code can be built with the project CMake
dnn: disable warning when loading a fp16 model #23853
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [ ] The feature is well documented and sample code can be built with the project CMake
Build Java without ANT #23724
### Pull Request Readiness Checklist
Enables a path of building Java bindings without ANT
* Able to build OpenCV JAR and Docs without ANT
```
-- Java:
-- ant: NO
-- JNI: /usr/lib/jvm/default-java/include /usr/lib/jvm/default-java/include/linux /usr/lib/jvm/default-java/include
-- Java wrappers: YES
-- Java tests: NO
```
* Possible to build OpenCV JAR without ANT but tests still require ANT
**Merge with**: https://github.com/opencv/opencv_contrib/pull/3502
Notes:
- Use `OPENCV_JAVA_IGNORE_ANT=1` to force "Java" flow for building Java bindings
- Java tests still require Apache ANT
- JAR doesn't include `.java` source code files.
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
DNN: fix bug for X86 Winograd #23763
Address https://github.com/opencv/opencv/issues/23760
The patch aims to add a runtime check for X86 platform without AVX(2).
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [ ] The feature is well documented and sample code can be built with the project CMake
Assertion Fix in Split Layer #23746
### Pull Request Readiness Checklist
This PR fixes issue mentioned in [#23663](https://github.com/opencv/opencv/issues/23663)
Merge with https://github.com/opencv/opencv_extra/pull/1067
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Support ONNX operator QLinearSoftmax in dnn #23655
Resolves https://github.com/opencv/opencv/issues/23636.
Merge with https://github.com/opencv/opencv_extra/pull/1064.
This PR maps the QLinearSoftmax (from com.microsoft domain) to SoftmaxInt8 in dnn along with some speed optimization.
Todo:
- [x] support QLinearSoftmax with opset = 13
- [x] add model and test data for QLinearSoftmax with opset = 13
- [x] ensure all models have dims >= 3.
- [x] add the script to generate model and test data
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
/build/build_cuda/3p/opencv/linux-x64/ubuntu22.04/Debug/modules/dnn/src/layers/cpu_kernels/convolution.cpp: In function 'void cv::dnn::packData8(char*&, float*&, int&, int&, int&, const int*, int, int, int)':
/build/build_cuda/3p/opencv/linux-x64/ubuntu22.04/Debug/modules/dnn/src/layers/cpu_kernels/convolution.cpp:448:43: error: 'CONV_NR' was not declared in this scope; did you mean 'CONV_3D'?
448 | vx_store(inpbufC_FP32 + k*CONV_NR, vx_load(inptrInC + k1));
| ^~~~~~~
| CONV_3D
LSTM ONNX Layout Attribute Support #23614
### Explanation
This PR contains necessary changes to support `layout` attribute. This attributes is present in [ONNX](https://github.com/onnx/onnx/blob/main/docs/Operators.md#lstm) and [Torch](https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html#lstm) (in touch it is name as `batch_first=True`) libraries. When `layout = 1` input to LSTM layer is expected to have batch dimension first -> `[batch_size, sequence_length, features]` vs `layout = 0` - default `[sequence_length, batch_size, features]`
### Test Data
Test data and data generator for PR located here [#1063](https://github.com/opencv/opencv_extra/pull/1063)
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Build DNN without Protobuf
DNN module can be built without Protobuf for Darknet, TFLite, OpenVINO, Torch (not PyTorch) models.
```
cmake \
-DCMAKE_BUILD_TYPE=Release \
-DBUILD_LIST=dnn \
-DWITH_PROTOBUF=OFF \
-DWITH_OPENCL=OFF
7.1M lib/libopencv_dnn.so.4.7.0
```
```
cmake \
-DCMAKE_BUILD_TYPE=Release \
-DBUILD_LIST=dnn \
-DWITH_OPENCL=OFF
3.9M lib/libopencv_dnn.so.4.7.0
```
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Import and inference INT8 quantized TFLite model #23409
### Pull Request Readiness Checklist
* Support quantized TFLite models
* Enable fused activations (FP32, INT8)
**Merge with extra**: https://github.com/opencv/opencv_extra/pull/1048
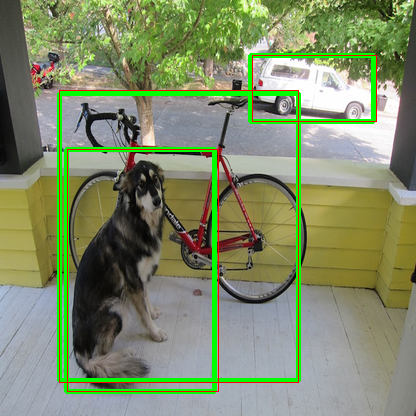
on the image, green boxes are from TFLite and red boxes from OpenCV
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Fix ONNX parser for single-layer LSTM hidden and cell states #23475
### Fix ONNX parser for single-layer LSTM hidden and cell states
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
This PR addresses #21118 [issue](https://github.com/opencv/opencv/issues/21118). The problem is that the ONNX parser is unable to read the hidden state and cell state for single-layer LSTMs. This PR fixes the issue by updating the parser to correctly read hidden and cell states.
DNN: Add New API blobFromImageParam #22750
The purpose of this PR:
1. Add new API `blobFromImageParam` to extend `blobFromImage` API. It can support the different data layout (NCHW or NHWC), and letter_box.
2. ~~`blobFromImage` can output `CV_16F`~~
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [ ] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [ ] The feature is well documented and sample code can be built with the project CMake
dnn: Support more operators in CANN backend #23401
This PR adds the support of following layers:
- [x] Sub
- [x] PRelu
- [x] DeConv
- [x] Also warn users if backend is switched back to default if some of the layers are not supported.
- [ ] [Dropped] LSTM: some hacks (adding layers) were introduced which makes it even harder to build the graph for CANN backend.
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Added LSTM and GRU tests for various batch and input length sizes #23501
Added tests with various sequence length and batch sizes
Test data: https://github.com/opencv/opencv_extra/pull/1057
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [ ] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Fix identifying initializers in ONNX graph simplification #23296
Fixes https://github.com/opencv/opencv/issues/23295
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
Propagate inputs info for ONNX and TFLite models
### Pull Request Readiness Checklist
Needed for generic applications such as benchmarking pipelines. So OpenCV can tell about the default input shapes specified in the models.
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
4 failed tests in open_test_dnn listed below:
* Test_Caffe_layers.Conv_Elu/0, where GetParam() = OCV/CPU
* Test_ONNX_layers.ConvResizePool1d/0, where GetParam() = OCV/CPU
* Test_TensorFlow_layers.tf_reshape_nhwc/0, where GetParam() = OCV/CPU
* Test_Torch_layers.net_inception_block/0, where GetParam() = OCV/CPU
In winofunc_AtXA_8x8_f32 and winofunc_BtXB_8x8_f32
implementation, incorrect input parameters cause tests failure.
Add four new different variables for the last four input parameters of
v_transpose4x4 to fix bugs, and update related comments.
Signed-off-by: tingbo.liao <tingbo.liao@starfivetech.com>
Related issue: https://github.com/opencv/opencv_zoo/issues/136
Features added:
- Support operators with multiple output: ONNX Split.
- Support Slice without steps.
Bugs fixed:
- Wrong settings in ClipByValue (Relu6).
- Wrong calculation of pads in convolution layer (It is wrong generally but only fixed specifically for CANN for now).
### Pull Request Readiness Checklist
See details at https://github.com/opencv/opencv/wiki/How_to_contribute#making-a-good-pull-request
- [x] I agree to contribute to the project under Apache 2 License.
- [x] To the best of my knowledge, the proposed patch is not based on a code under GPL or another license that is incompatible with OpenCV
- [x] The PR is proposed to the proper branch
- [x] There is a reference to the original bug report and related work
- [x] There is accuracy test, performance test and test data in opencv_extra repository, if applicable
Patch to opencv_extra has the same branch name.
- [x] The feature is well documented and sample code can be built with the project CMake
dnn: add layer normalization for vision transformers
* add layer norm onnx parser, impl and tests
* add onnx graph simplifier for layer norm expanded
* handle the case when constants are of type Initializer
* add test case for layer norm expanded with initializers
* use CV_Assert & CV_CheckType in place of CV_Assert_N; use forward_fallback for OCL_FP16
* use const ref / ref in parameters of invoker::run; extract inner const if from nested loop; use size_t in place of ull
* template hasBias
* remove trailing whitespace
* use pointer parameter with null check; move normSize division & mean_square division outside of loop; use std::max to ensure positive value before std::sqrt
* refactor implementation, optimize parallel_for
* disable layer norm expanded
* remove the removal of layer norm optional outputs
{kind=link}