Introduction
When talking about file systems, many people would assume directories, list files under a directory, etc. These are expected if we want to hook up SeaweedFS with linux by FUSE, or with Hadoop, etc.
Sample usage
First, run weed scaffold -config=filer to see an example filer.toml file. Copy it out and read it, create the data store if needed.
The simplest filer.toml can be:
[leveldb2]
enabled = true
dir = "." # directory to store level db files
Two ways to start a weed filer
# assuming you already started weed master and weed volume
weed filer
# Or assuming you have nothing started yet,
# this command starts master server, volume server, and filer in one shot.
# It's strictly the same as starting them separately.
weed server -filer=true
Now you can add/delete files, and even browse the sub directories and files
# POST a file and read it back
curl -F "filename=@README.md" "http://localhost:8888/path/to/sources/"
curl "http://localhost:8888/path/to/sources/README.md"
# POST a file with a new name and read it back
curl -F "filename=@Makefile" "http://localhost:8888/path/to/sources/new_name"
curl "http://localhost:8888/path/to/sources/new_name"
# list sub folders and files, use browser to visit this url: "http://localhost:8888/path/to/"
# To list the results in JSON:
curl -H "Accept: application/json" "http://localhost:8888/path/to"
# To list the results in pretty JSON
curl -H "Accept: application/json" "http://localhost:8888/path/to?pretty=y"
# The directory list limit is default to 100
# if lots of files under this folder, here is a way to efficiently paginate through all of them
http://localhost:8888/path/to/sources/?lastFileName=abc.txt&limit=50
Architecture
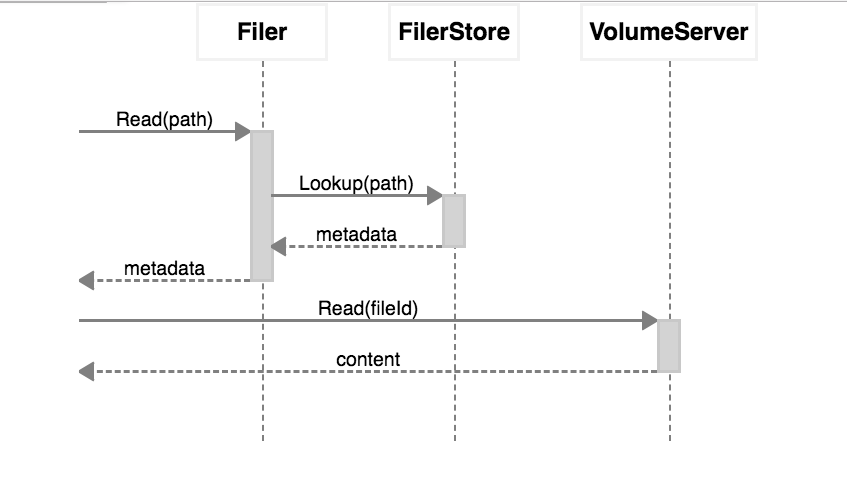
Filer has a persistent client connecting to Master, to get the location updates of all volumes. There are no network round trip to lookup the volume id location.
For file reads:
- Filer lookup metadata from Filer Store, which can be Cassandra/Mysql/Postgres/Redis/LevelDB/etcd/Sqlite.
- Filer read from volume servers and pass along to the read request.
For file writes:
- Client stream files to Filer
- Filer uploads data to Weed Volume Servers, and break the large files into chunks.
- Filer writes the metadata and chunk information into Filer store.
Filer Store
Complexity
For one file retrieval, the (file_parent_directory, fileName)=>meta data lookup will be O(logN) for LSM tree or Btree implementations, where N is number of existing entries, or O(1) for Redis.
For file listing under a particular directory, the listing is just a simple scan for LSM tree or Btree, or O(1) for Redis.
For adding one file, the parent directories will be recursively created if not exists. And then the file entry will be created.
For file renaming, it is just O(1) operations, with deleting the old metadata and inserting the new metadata, without changing the actual file content on volume servers.
For directory renaming, it will be O(N) operations, with N as the number of files and folders underneath the to-be-renamed directory. This is because each of them will need to adjust the metadata. But still there are no change for the actual file content on volume servers.
Use Cases
Clients can assess one "weed filer" via HTTP, list files under a directory, create files via HTTP POST, read files via HTTP GET directly.
Although one "weed filer" can only sit in one machine, you can start multiple "weed filer" on several machines, each "weed filer" instance running in its own collection, having its own namespace, but sharing the same SeaweedFS storage.
Filer Linearly Scalable
Filer is designed to be linearly scalable, and only limited by the underlying meta data storage.
Filer Work Loads
Filer has two use cases.
When filer is used directly to upload and download files, and when used together with "weed s3", the filer also need to process the file content during read and write in addition to meta data. So it's a good idea to add multiple filer servers.
When filer is used with "weed mount", the filer only provides file meta data retrieval. The actual file content are read and write directly between "weed mount" and "weed volume" servers. So the filer is not that much loaded.